.png)
Deze blogpost behandelt hoe u functioneel programmeren in C# kunt benutten met behulp van een paar eenvoudige klassen en uitbreidingsmethoden, met inzichten die toepasbaar zijn op andere moderne talen die lambda-expressies of afsluitingen ondersteunen.
Na meer dan 15 jaar C# code te hebben geschreven, gericht op Object Oriented Programming, heb ik me onlangs gewaagd aan de programmeertaal Rust, bekend om zijn functionele programmeermogelijkheden. Toen ik de mogelijkheden van Rust begon te waarderen, zoals Options, Results en Map functies, vroeg ik me af hoe ik de principes van functioneel programmeren kon integreren in mijn C# ontwikkeling.
Alle code voor deze blogpost is te vinden in deze Github repository
Kenmerken van functioneel programmeren
Voordat we in de code duiken, moet ik eerst iets verduidelijken over de kenmerken van functioneel programmeren.
Functioneel programmeren is een programmeerparadigma dat de nadruk legt op onveranderlijkheid, het gebruik van zuivere functies en het vermijden van neveneffecten. De belangrijkste kenmerken zijn de behandeling van functies als eersteklas burgers, waardoor ze kunnen worden doorgegeven als argumenten, teruggegeven door andere functies, en opgeslagen in gegevensstructuren. Functioneel programmeren bevordert ook het gebruik van hogere-orde functies die andere functies als invoer nemen of als uitvoer teruggeven. Recursie wordt vaak verkozen boven lusconstructies, en het gebruik van onveranderlijke gegevensstructuren zorgt ervoor dat gegevens ongewijzigd blijven tijdens de uitvoering van het programma. Dit paradigma leidt uiteindelijk tot meer voorspelbare, beknopte en onderhoudbare code, waardoor het steeds populairder wordt onder ontwikkelaars vanwege zijn vermogen om complexiteit te beheersen en robuust softwareontwerp te bevorderen.
- Onwijzigbaarheid: Gegevens blijven ongewijzigd tijdens de uitvoering van het programma, waardoor het risico van onbedoelde neveneffecten afneemt.
- Zuivere functies: Functies zijn uitsluitend afhankelijk van hun invoer en produceren consistente uitvoer zonder neveneffecten te veroorzaken.
- Eersteklas functies: Functies kunnen worden doorgegeven als argumenten, teruggegeven door andere functies, en opgeslagen in gegevensstructuren.
- Hogere-orde functies: Functies die andere functies als invoer accepteren of als uitvoer teruggeven, waardoor krachtige compositie- en abstractietechnieken mogelijk zijn.
- Recursie: Herhaalde functieaanroepen om problemen op te lossen, vaak gebruikt als alternatief voor lusconstructies.
- Declaratief programmeren: Code richt zich op het uitdrukken van wat er moet gebeuren, in plaats van het gedetailleerd beschrijven van stap-voor-stap procedures.
- Luie evaluatie: Berekening wordt uitgesteld tot het absoluut noodzakelijk is, waardoor de prestaties verbeteren en onnodig werk wordt vermeden.
- Patroonmatching: Een flexibele manier om gegevens te destructureren en specifieke patronen te matchen, waardoor beknopte en leesbare code ontstaat.
- Type-inferentie: Automatische bepaling van datatypes door de compiler, waardoor expliciete type-annotaties minder nodig zijn.
- Referentiële transparantie: Functies met dezelfde invoer produceren altijd dezelfde uitvoer, waardoor code gemakkelijker te beredeneren en te testen is.
Problemen met imperatief programmeren
Laten we beginnen met een snel voorbeeld: Celsius omrekenen naar Fahrenheit.
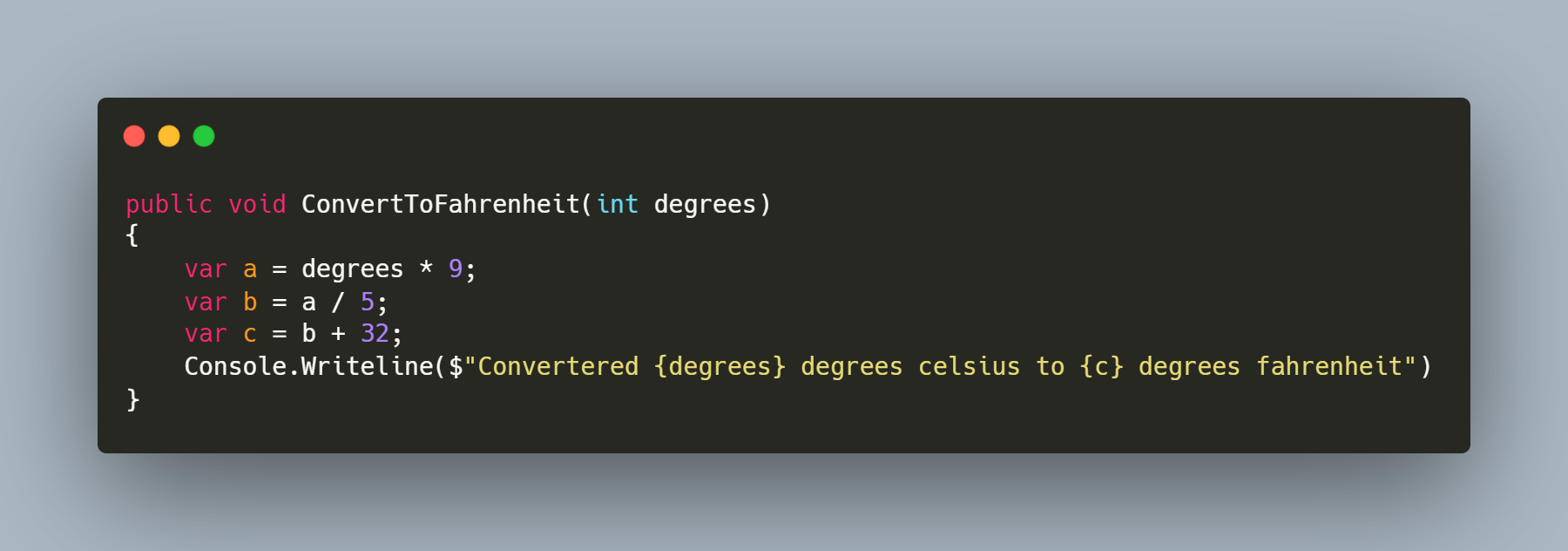
Opmerkelijk is dat a, b en c een langere levensduur hebben dan nodig en onbedoeld elders in de code kunnen worden gebruikt. Dit kan leiden tot onverwachte resultaten, dus het is belangrijk voorzichtig te zijn met het hergebruik van variabelen buiten hun bedoelde bereik.
Hoewel het voor de hand liggend lijkt, heb ik deze fout meer dan eens zien gebeuren in grotere code-implementaties. Om onverwachte resultaten te voorkomen, is het het beste om tussenliggende waarden te elimineren zodra ze niet langer nodig zijn. Dit helpt onbedoeld hergebruik van variabelen buiten hun bedoelde bereik te voorkomen.
.png)
Scoping en mutabiliteit
Scoping en mutabiliteit zijn belangrijke concepten om in gedachten te houden wanneer men werkt met variabelen in een programma. De functie Map neemt een waarde en een conversiefunctie, waarmee waarden op een duidelijke en beknopte manier kunnen worden getransformeerd. Ter illustratie het volgende voorbeeld:
.png)
Door deze methode te gebruiken, kan ik dezelfde stappen uitvoeren als voorheen, terwijl ik ervoor zorg dat de tussenliggende waarden de juiste scoped hebben. Aangezien de geconverteerde waarde wordt teruggegeven, kunnen we er onmiddellijk een nieuwe Map-functie aan koppelen en de verwerking voortzetten zonder ons zorgen te hoeven maken over onbedoeld hergebruik van variabelen.
.png)
Het declaratief maken
Hoewel de vorige functie ervoor zorgt dat tussenliggende waarden kortstondig en onveranderlijk zijn, kan het nog steeds een uitdaging zijn om te lezen en te begrijpen. Echter, door het declaratiever te maken, kunnen we onze aandacht verleggen naar wat we willen bereiken in plaats van hoe het te doen. Eén benadering om dit te bereiken is door gebruik te maken van een techniek die currying heet.
Currying zet een functie met meerdere argumenten om in een reeks functies met één argument die een andere functie teruggeven, totdat alle benodigde argumenten zijn gegeven.
Ter illustratie het volgende voorbeeld van een curryfunctie:
.png)
Wat precies hetzelfde doet als dit volledig geschreven voorbeeld.
.png)
De functie Vermenigvuldigen neemt een parameter (de vermenigvuldigingsfactor) en geeft een nieuwe functie terug die een gegeven waarde vermenigvuldigt met de opgegeven vermenigvuldigingsfactor. Wanneer je een curried-functie aanroept, kun je dat doen door de argumenten één voor één te geven, zoals dit:
.png)
Hoewel het op het eerste gezicht onconventioneel lijkt, is wat we hier doen eigenlijk een voorbeeld van gedeeltelijke toepassing. Met gedeeltelijke toepassing kun je sommige argumenten van tevoren opgeven en die gedeeltelijke toepassing zo vaak als nodig hergebruiken. Dit kan een krachtige techniek zijn, afhankelijk van de toepassing waar je aan werkt, dus neem even de tijd om het te laten bezinken.
.png)
Laten we nu eens bekijken hoe we deze curryfuncties kunnen gebruiken met onze Map-functie om de nodige transformaties toe te passen:
.png)
Om het proces nog verder te vereenvoudigen, kunnen we gebruik maken van de stenografische notatie die C# biedt om de curried functies toe te passen:
.png)
Door een declaratieve benadering toe te passen die onveranderlijke waarden gebruikt, hebben we nu een duidelijke en beknopte conversie van Celsius naar Fahrenheit die gemakkelijk te lezen is en veel minder vatbaar voor fouten.
Maar dat lijkt veel werk, voor zo'n eenvoudige taak Thomas.
Hoewel het misschien veel werk lijkt voor zo'n eenvoudige taak, is het belangrijk om in gedachten te houden dat de functies die we gemaakt hebben verpakt en hergebruikt kunnen worden in meerdere projecten. Dit maakt de investering in tijd en moeite om ze te maken op de lange termijn de moeite waard, omdat het kan leiden tot meer efficiëntie en consistentie in je codebase.
Functionele validatie
Laten we nu een groter voorbeeld bekijken: het valideren van een Nederlands telefoonnummer. Hoewel we in dit voorbeeld geen reguliere expressies zullen gebruiken, geven we een imperatieve implementatie om het concept te illustreren.
.png)
Om een telefoonnummer te valideren zijn er verschillende stappen nodig. Als één van deze stappen mislukt, is het belangrijk om zo vroeg mogelijk terug te keren om CPU-cycli te besparen. De imperatieve benadering die wordt gebruikt om dit te bereiken, richt zich echter vooral op hoe het telefoonnummer moet worden gevalideerd, in plaats van op wat we eigenlijk willen bereiken. Dit kan leiden tot veel ruis, met if checks en return statements die de code moeilijk leesbaar maken.
Om dit probleem aan te pakken, kunnen we een functie van hogere orde gebruiken en een reeks validatiefuncties doorgeven om over te aggregeren. Zo kunnen we ons meer richten op het wat van het probleem, dan op het hoe.
Eerst moeten we de verschillende validaties opsplitsen in functies met een naam.
.png)
Hiermee wordt hetzelfde resultaat bereikt als met de vorige imperatieve aanpak, maar met de validaties opgesplitst in benoemde functies.
Nu kunnen we dit verder verbeteren door een functie van hogere orde te gebruiken om de validatiefuncties te aggregeren. We kunnen een Validate extension method maken die alle validatiefuncties als argumenten neemt.
.png)
De methode All die op de predicaten wordt gebruikt is een nuttige functie, omdat deze false teruggeeft zodra een van de predicaten niet true teruggeeft, wat overeenkomt met de vroege return false verklaringen die in de imperatieve implementatie worden gebruikt. Door de Validate-methode te gebruiken op het telefoonnummer zelf, kunnen we het nummer gemakkelijk valideren met een declaratieve aanpak met beter leesbare code die zich richt op wat we willen in plaats van hoe we het willen valideren.
.png)
Extra validaties toevoegen wordt veel gemakkelijker, omdat we ze gewoon kunnen toevoegen aan de lijst van validaties zonder ons zorgen te maken over de controlestroom van een imperatieve implementatie.
Anonieme functies kunnen ook worden gebruikt in plaats van genoemde functies voor beknoptere code. Hier is een voorbeeld waarbij anonieme functies worden gebruikt om een gebruikersnaam te valideren.
.png)
Monads
In veel gevallen moeten we gegevens in een reeks stappen omzetten in een andere vorm. Neem bijvoorbeeld deze klasse Person
.png)
Als we een persoonsrecord hebben en we willen de voornaam van de echtgenoot opvragen, kunnen we dat als volgt doen:
.png)
Echter, afhankelijk van de taalversie en de nul-instellingen voor uw project, kan elk van deze waarden nul zijn, ondanks wat de compiler suggereert, en zou de bewerking tijdens runtime mislukken. Om dit aan te pakken zouden we null-controles moeten toevoegen.
.png)
Deze aanpak voegt veel rommel toe aan onze code en haalt de aandacht weg van wat we proberen te bereiken. Om dit te vermijden, kunnen we een ontwerppatroon gebruiken waarbij de implementatie van de pijplijn wordt geabstraheerd door een waarde in te pakken in een type. Dit patroon heet een Monad, waarover je meer kunt leren in het functioneel programmeren paradigma. Binnen functioneel programmeren vind je types als Resultaat of Optie (ook wel Misschien genoemd) die de waarden voor elk resultaat in een pijplijn omhullen.
Zo ziet ons optietype eruit:
.png)
Voor ons Optie-type zal ik 2 subtypes definiëren: Some en None:
.png)
Een waarde kan impliciet worden geconverteerd naar Some als de waarde niet nul is, en kan impliciet worden geconverteerd naar None als de waarde nul is.
Laten we nu onze mapping functie een beetje uitbreiden:
.png)
In dit geval controleren we eerst of de verkregen waarde werkelijk een waarde is of dat het None is. Als we een None waarde krijgen, geven we gewoon weer een None terug.
Als we een Some-waarde hebben, kunnen we nu veilig proberen de waarde te mappen met behulp van de meegeleverde fabrieksmethode. Als de mapping mislukt, geven we geen terug. Anders geven we een nieuwe Some-waarde terug die het in kaart gebrachte resultaat bevat.
Door deze logica weg te abstraheren in de Map-methode, kunnen we onze aanroepen nu ketenen zonder ons zorgen te maken over control flow of null-controles. Hierdoor kunnen we ons concentreren op de gegevenstransformaties die we willen bereiken, in plaats van op de boilerplate-code voor de afhandeling van nulwaarden.
.png)
Als de persoon geen is, of de echtgenoot geen is, of de voornaam van de echtgenoot geen is, geven we gewoon geen terug. Als alle waarden zijn ingesteld, wordt de voornaam van de echtgenoot teruggegeven.
Wij kunnen deze bewerkingen blijven volgen om de gegevens naar behoefte te verwerken.
.png)
De code in de vorige paragraaf illustreert een situatie waarin we de echtgenoot van de echtgenoot van de echtgenoot krijgen, enzovoort, totdat we uiteindelijk ergens in de keten een nulwaarde tegenkomen. Deze aanpak staat ook bekend als "Spoorgeoriënteerd programmeren", waarbij de nadruk ligt op het lineair afhandelen van succes- en faalpaden.
Het uitvoeren van intermediaire logica
Soms wilt u aanvullende logica opnemen in de eerder genoemde pijplijnen. U kunt bijvoorbeeld een tussenliggende waarde willen loggen voordat u verdere bewerkingen uitvoert op hetzelfde resultaat.
.png)
Functionele programmering kan worden gebruikt om dit doel te bereiken door een functie te creëren die bekend staat als Tee.
De term "Tee" is genoemd naar het Unix-commando "tee", dat genoemd is naar de T-vormige pijpverbinding.
.png)
We kunnen nu hetzelfde bereiken, maar de Tee-functie aanroepen waar we willen:
.png)
Zoals u ziet, is de logica voor het afdrukken of de echtgenoot een waarde heeft nu gegroepeerd binnen hetzelfde bereik, en niet verdeeld over meerdere regels. Nadat we klaar zijn met het loggen van de waarde van de echtgenoot, kunnen we verdergaan met de mapping zoals voorheen. Hierdoor kunnen we extra bewerkingen uitvoeren op hetzelfde resultaat zonder de pijplijn te verbreken, wat onze code leesbaarder en beter onderhoudbaar maakt.
Mutabiliteit
Ik vind het erg prettig dat de programmeertaal Rust is ontworpen om standaard onveranderlijk te zijn, tenzij anders gespecificeerd, wat in het begin voor sommige ontwikkelaars een uitdaging kan zijn. Het is echter een goede gewoonte om te overwegen of een waarde muteerbaar moet zijn of niet, omdat veel problemen met toestand en concurrency tot verschillende bugs kunnen leiden. Door standaard immutabiliteit te kiezen, dwingen we onszelf om beter over deze zaken na te denken.
In C# heeft de introductie van records en de with operator het veel gemakkelijker gemaakt om onveranderlijke types en waarden te hebben. In ons persoonsrecord zijn de velden onveranderlijk, zodat ze slechts eenmaal in een instantie kunnen worden ingesteld.
.png)
Onze compiler kan het bovenstaande codefragment niet compileren, omdat de eigenschappen van de persoonsregistratie alleen kunnen worden ingesteld wanneer de instantie wordt geïnstantieerd. Daarom hebben we eigenlijk een bijgewerkte versie van die instantie nodig. Met de with operator kunnen we een kopie maken van de oorspronkelijke record, waarbij we de leden initialiseren met dezelfde waarden als het origineel, of een andere waarde indien gespecificeerd in de with operator. Aangezien de velden van onze persoonsrecord onveranderlijk zijn, zal dit een nieuwe instantie van de persoonsrecord aanmaken met de bijgewerkte velden.
.png)
Als een andere thread langskomt en het privé-veld _person ergens in onze reeks wijzigt, zou onze test nog steeds slagen, omdat we niet verwijzen naar een muteerbare instantie. Dit is een uitstekend voorbeeld van pure functies, waar we geen neveneffecten hebben.
Referenties
Als u dit in uw eigen project wilt gebruiken, zijn er een aantal pakketten die u in uw project kunt opnemen om snel aan de slag te gaan:
- LanguageExt
- RSharp (geschreven door ondergetekende)
- CSharpFunctionalExtensions
Ook een grote shoutout naar Simon Painter voor het leveren van uitstekende inhoud via YouTube.
Slotwoord
Ik hoop dat je genoten hebt van dit bericht over functioneel programmeren. Door gebruik te maken van deze concepten kunnen we meer onderhoudbare, herbruikbare en testbare code maken. Hoewel functioneel programmeren in het begin ontmoedigend kan zijn, kan het met een beetje oefening en experimenteren een zeer krachtig hulpmiddel zijn in je ontwikkelingsarsenaal. Ik hoop dat je dit bericht informatief en waardevol vond.
Bedankt voor het lezen!





